AN AI UNSUPERVISED CLUSTERING OF AIRPORTS
A tool to find suitable humanitarian cooperation for disaster preparedness
In collaboration with Maria Browarska
In recent years, natural disasters have increased in frequency, causing significant damage to communities and infrastructure worldwide. When a natural disaster strikes, airports in the affected region have to adapt quickly from serving regular passengers to becoming a humanitarian hub handling a massive increase in passengers and cargo. Several countries are particularly vulnerable and prone to such a devastating event. Although existing initiatives aim to raise awareness and improve airport preparedness, authorities are often isolated in their resilience efforts as they tend to act individually, and their response is often bound by local experience. Consequently, this research aims to broaden the field of view from a local to a global one by compiling a database of 971 airports worldwide with corresponding socio-technical characteristics in various data modalities. In addition, through a data science approach, a transformation of the different data modalities was performed to extract numerical feature vectors so that in future studies a correlation between airports can be found, to find similar airports from which different approaches to disaster preparedness and response can be learned.
This article explores how data science could help establish a base for forming collaborations between airports that might face similar challenges in disaster preparedness efforts. The goal is to build a comprehensive database describing airports from the perspective of their disaster preparedness that will help future researchers find similarities between them, based on their intrinsic socio-technical features, so that perhaps an airport in Indonesia could be matched with its sibling airport in the Caribbeans. The research involved several programming operations––starting with collecting data, through data processing, up to experimenting with Self Organising Maps (SOM) algorithm in order to find airports that share features that are relevant in terms of their disaster preparedness. The database can be found in the following repository.
With this article, we want to describe the steps from collection, normalization, and pre-processing of the data to transforming the multimodality of the gathered data to a numerical feature vector that can be used for the grouping of similar airports through Unsupervised Machine Learning algorithms that can cluster similar airports based on similar numerical features. Having a relevant scenario to apply ML that benefits society at large.
The main objectives of this paper are:
A) To better understand the challenges that airports face when a natural disaster strikes and their preparedness activities.
B) Then it shall be translated into a list of socio-technical features influencing the level of preparedness and airport capabilities in facing a disaster.
C) The finding of key features is relevant for building a database containing valuable humanitarian aid-related information about several airports worldwide, composed solely from publicly available sources.
The focus on publicly available data is conditioned by a large number of airports being analyzed, which makes it impossible to conduct surveys and obtain information directly within the resources and time frame of this research.
971 airports chosen to be analyzed
In order to cluster airports based on their distinctive features relevant for disaster preparedness, an unsupervised machine learning algorithm was applied with the use of SOMPY Python library ([22]). The whole process was thoroughly documented in the attached GitLab repository.
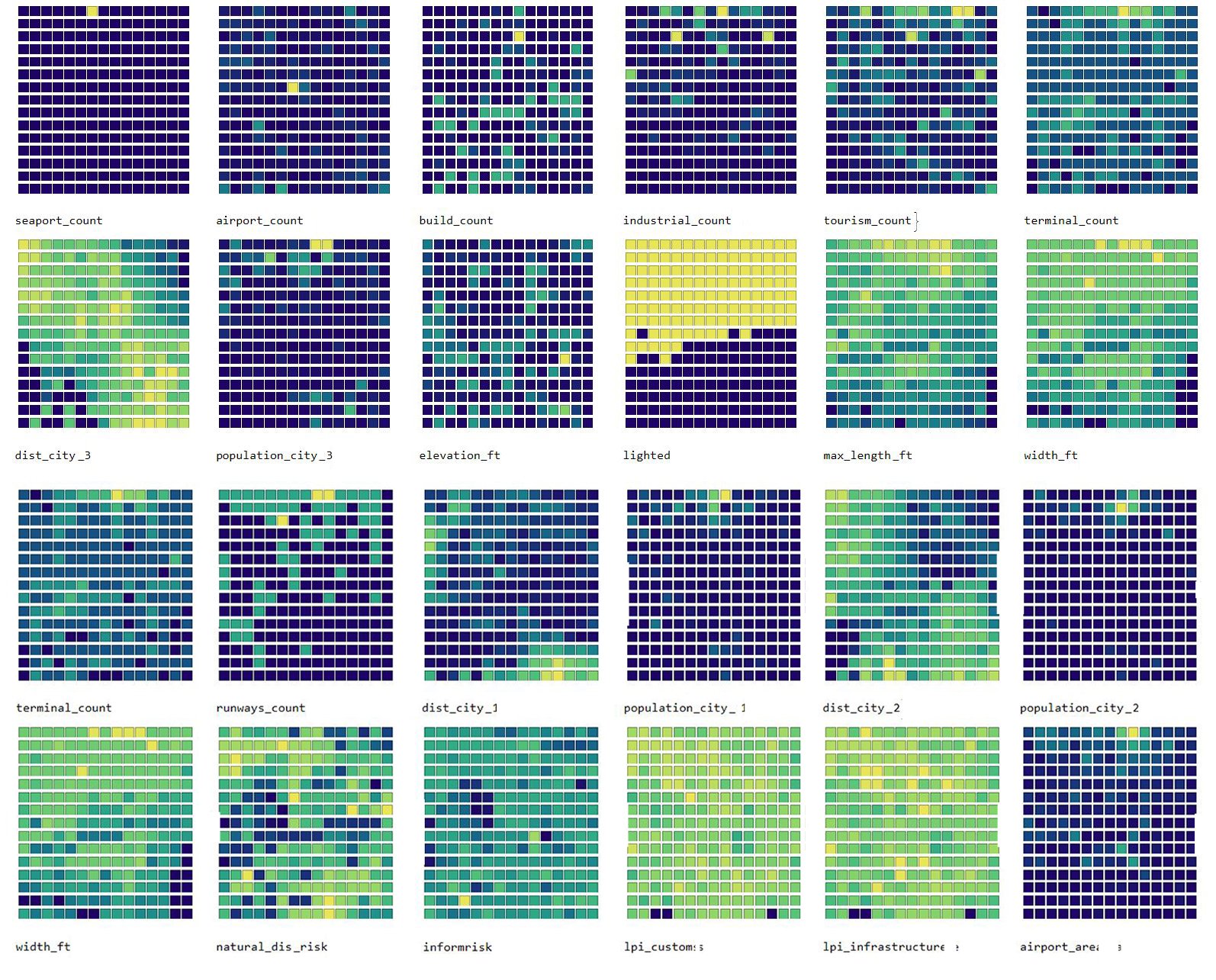
Visualisation of each feature
The data set consisting of 971 records with airports and their features was split into two smaller sets the training set with randomly chosen 70% of all records, and the testing set with the remaining 30% - resulting in the training set with 650 data points and the test set with data points.
After the pre-processing was finished, all records from the training set were transformed into input vectors that can be processed by the SOM. For the first attempt each vector was a series of 36 numerical values, describing all the chosen features for each airport. Within the SOMPY API, each vector was normalised before the training of the SOM.
The training phase was repeated 100 times for various, randomly chosen sizes of the final SOM map, in order to find the best performing one, based on the calculated topographic and quantisation error of each training run. The smaller these values, the better the performance of the feature map ([1]). Once the best performing map was chosen, a visualisation of each feature on a map was performed, as shown in above figure.
Clustering
The above figure is an example of the results of clustering a SOM, with airports grouped in one cell showing strong similarity in the low number of alternative seaports and airports, and medium traffic type, could be used to form a cooperation focusing on ways of preparing an airport with these specific conditions. Even though the airports themselves can be in distant parts of the world, their preparedness strategies can be similar, given their dominant features. Of course, these are only a couple of areas in which these airports can be seen as similar, and it is important to note the possible organisational and cultural differences. While the airport authority feature aims at describing the possible organisational scheme, there still might be more factors at place.
The database built in this article is a valuable resource for future clustering analysis or future research related to airports’ preparedness for humanitarian disasters. It can be further analyzed in more detailed research, updated accordingly, and used to assess airports’ venerability and preparedness. From the scientific perspective, this article proves that there are now ways of analyzing complex, specific challenges with a global overview based on numerous publicly available data sets. It also shows that scientists need to be very careful when using not precisely scientific sources and that building a specific, tailored database is a lengthy, challenging process. Nevertheless, it can be achieved not only by IT professionals but also by multidisciplinary researchers. This article provided a valuable framework for approaching complex socio-technical environments of airports and their disaster preparedness, through building a database with relevant features, based on interviews and literature review, using only publicly available data, followed by a comprehensive data selection, collection and pre-processing.
The challenges and problems encountered along the way, both solved, and unsolved can form a valuable tool for other professionals and scientists willing to conduct similar research, not only related to the domain of aviation and disaster preparedness.
An additional finding is that we identified the need for a common, reliable database with all relevant information about airports in vulnerable locations. The one designed during this research could form a base for a one built with official data sources that are otherwise unavailable to the public. With that, however, comes the challenge of security; since detailed information about airports can be viewed as sensitive data, therefore access to such a database should be regulated.
Gallery